In this article we will go over the difference between a paragraph and a line break and how to insert each one.
Paragraphs - Press Enter
Paragraphs in the content are separated by a small amount of padding between them, usually the height of a line of text. Visually, it looks as though there is a blank line separating the 2 paragraphs.
When you press enter in the WYSIWYG editor it ends the current paragraph that you are typing and moves the cursor down to a new paragraph. When this happens an opening paragraph tag is created ( <p> ) beneath the closing paragraph tag ( </p> ) for the paragraph you are currently editing. Below you can see the WYSIWYG editor with a Heading 1 at the top and 2 paragraphs beneath it.
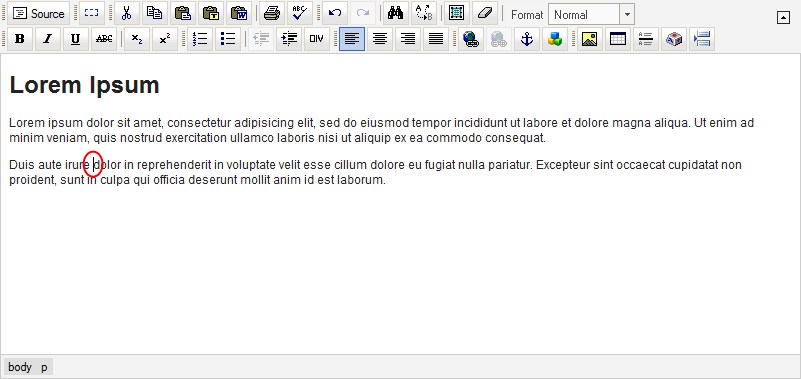
When we press the "Source" button we can review the source code behind what we've typed in so far:
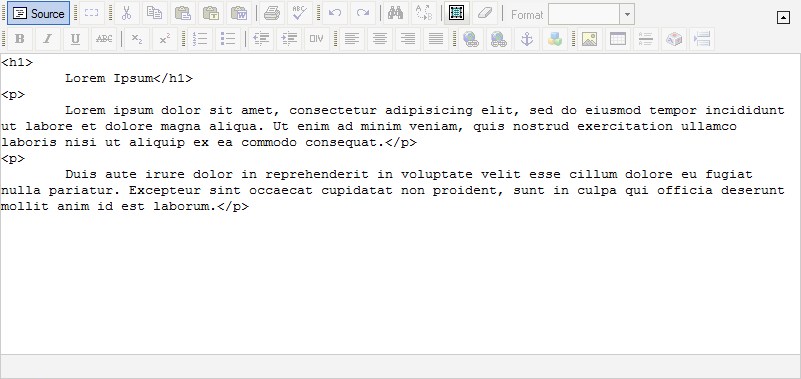
You can see above that there are 2 sets of <p> </p> tags in the HTML code, and each set contains the text for each paragraph. If you press enter at the end of the second paragraph then a blank set of <p> </p> tags will be inserted ready for you to type in.
Line Breaks - Hold Shift and Press Enter
When a line break is inserted the cursor moves down a single line, which is different from the paragraph which ends the paragraph and starts a new one. When you hold Shift and press Enter a line break tag is inserted ( <br /> ) and the text entered after the line break will appear on the next line down.
Using our previous screenshots above, if I place my cursor after "Duis aute irure" in the second paragraph and press Shift Enter then all the text after "Duis aute irure" will be shifted down by 1 line. So first of all, we place the cursor after "Duis arte irure":
Hold Shift and press Enter:
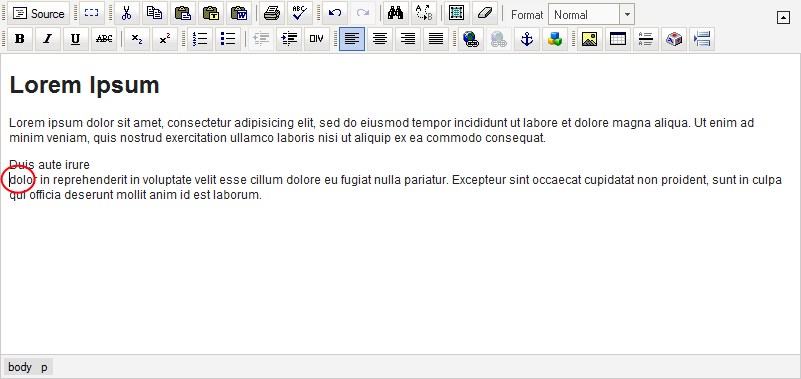
Now select the Source button to review the HTML code:
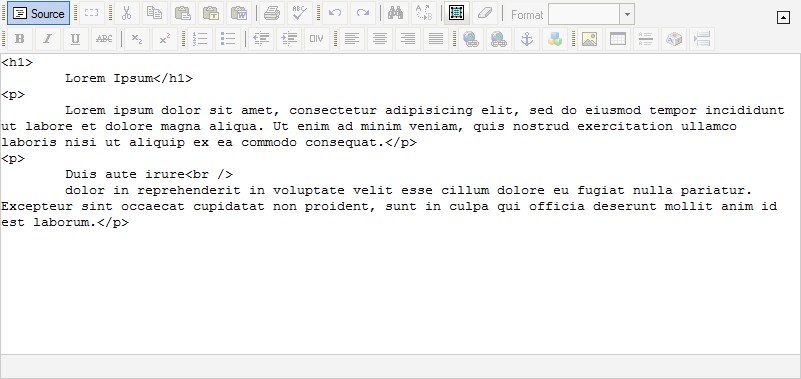
You can see above that after "Dui aute irure" a line break tag has been inserted ( <br /> ) and all the text after that is on the next line down. Even if we moved the line of text starting with "dolor" up a line so it's immediately following the <br /> tag the text would still appear on a new line in non-source view because as long as that <br /> tag is in the source code then anything following it will be on a new line.